Introducing DocumentCloud’s latest Add-On: A simplified Scraper tool that, with just a few clicks, monitors the website of your choosing, automatically downloads and indexes any newly uploaded documents and then alerts you if there is something of interest.
This builds on DocumentCloud’s Add-Ons platform we launched earlier this year, and with the Scraper we have launched a few new features that all Add-On creators and users can take advantage of, including scheduling Add-Ons, more detailed logging and the ability to directly import your own Add-Ons so you can remix others’ code to suit your own needs.
Watchdogging reading rooms made easy
We owe a big thanks to the Associated Press and Samantha Sunne for helping us test and pilot this approach for the Local News AI Readiness Workshops, a free training series helping dive into how machine learning and automation can drive more effective local reporting. Today’s launch iterates and simplifies the approach we developed for that program, getting rid of the need for a GitHub account and greatly reducing the steps to get started. All you need is a verified MuckRock account.
Verification is free but currently requires an affiliation with a newsroom, non-profit, research institution or other organization with a track record of publishing verified primary source materials. Learn more and apply for verification here if not already verified.
Once verified, to use the Scraper just follow these steps:
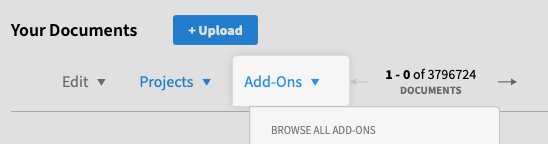
1. On DocumentCloud, under Add-Ons click Browse All Add-Ons:
2. If necessary, search for Scraper and then click Active (you’ll only need to do these two steps once):
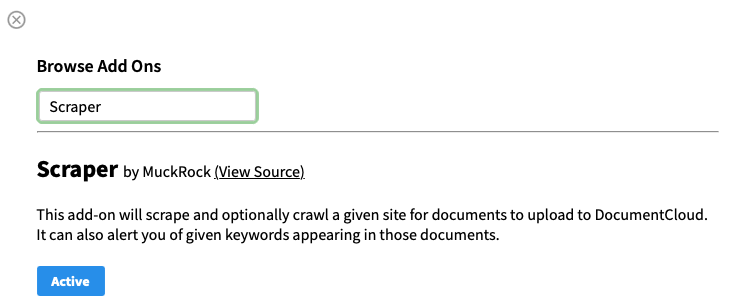
While in this dialogue, feel free to explore and activate some other Add-Ons that look interesting!
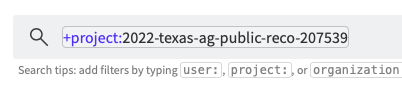
3. Create a new Project for newly scraped documents. Click Projects and then +New Projects. Find the newly created project in the sidebar and click it, and note the project ID (the numbers at the end of the project name in the search bar.
4. Close out the window by clicking X in the top left-hand of the dialog box. Under Add-Ons, you’ll now see Scraper. Click it to bring up the Scraper dialogue:
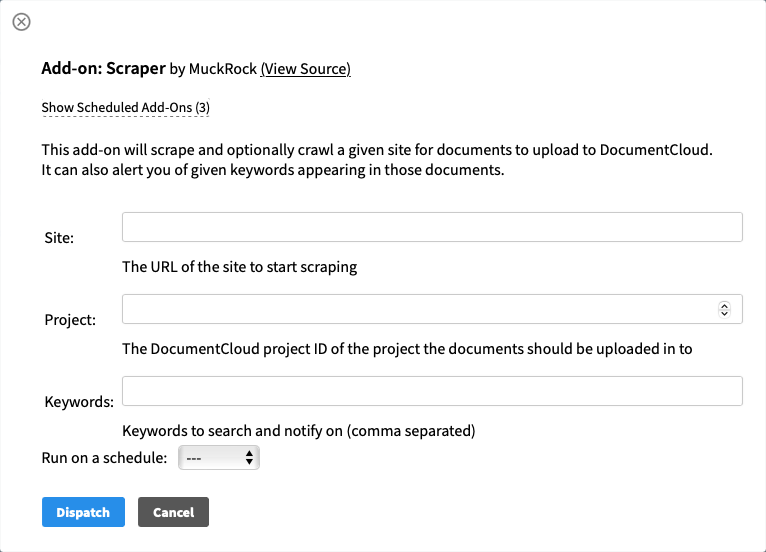
Put in the URL you’d like to monitor under Site, put the project ID where you’d like any detected documents added (this is a required field) and finally add some optional keywords you’d like to get flagged for alerts about (for example, “contract” will send you a notification email if documents uploaded there include that word).
By default, this Scraper will just run once upon activation, so go ahead and pick a schedule (hourly, daily or weekly) and DocumentCloud will automatically scrape any documents uploaded to the given URL. You’ll get an alert anytime it finds something new as well as an additional alert anytime something matches the criteria you defined.
To modify a recurring Add-On, click Show Scheduled Add-Ons and then pick the one you’d like to edit. You can tweak any of the variables or turn it off entirely at any time.
Join us Thursday to share how to improve this tool or to build your own
If you would like to see exactly how the Scraper Add-On works, you can take a look at its repository — it runs right off GitHub, so what you see there is the code that will run. Even better, you can make a pull request to suggest changes and improvements. The only code you should need to modify is the main.py file, and if we accept your pull request those improvements will be available to everyone.
If you’ve got another idea that takes the scraper in a different direction (or you’re building something totally new), you can now also install and run your own Add-Ons, linking your GitHub account to let you build your own features on the fly. Read our guide here on how to get started, as well as see a few example Add-Ons you can use as a base for your own creations. We’d love to hear how it goes.
We’re also hosting a season Thursday afternoon at 2 p.m. Eastern to hear your feedback, and we would love to get thoughts and ideas from both people who are end users of DocumentCloud on what kinds of features we should prioritize as well as how we can make it easier for developers to bring their ideas to life.
Come help build a more transparent future
If you’re excited about more open access to primary source materials, data and the tools powering an informed democracy, we’d love to talk! MuckRock is hiring a range of positions including journalism roles, software development and our first Chief Operating Officer.