9283 Tags
release notes
1 Project
DockIns: Machine Learning on Deadline for Journalists
130 Articles

Release Notes: Making it easier to sort, filter and reprocess document OCR
Since our last release notes, we released a new Add-On OCR Tagger that allows you to tag your document(s) based on the OCR engine used and we added better logging for when scheduled Add-Ons like Klaxon or Scraper get disabled. This helps more easily diagnose and correct outages that impact Add-Ons.
Release Notes: Improved sorting, new revision control documentation and more
In recent weeks, we’ve rolled out a few updates on DocumentCloud. Users can now sort documents on DocumentCloud by their key/value pairs. We’ve documented API access for document revision control. Finally, a fellow DocumentCloud user contributed a write-up on how to run your own version of Klaxon.
Release Notes: How to make self-hosted maps that work everywhere and cost next to nothing
Can we build a better way to build — and maintain — maps? DocumentCloud developer Chris Amico shares his recent work exploring new advances and opportunities when it comes to self-hosting maps.
Release Notes: Better site monitoring, revision control enhancements and more
MuckRock’s tech team has been hard at work enhancing our transparency platforms, all of which are open source. Read on for what’s changed.
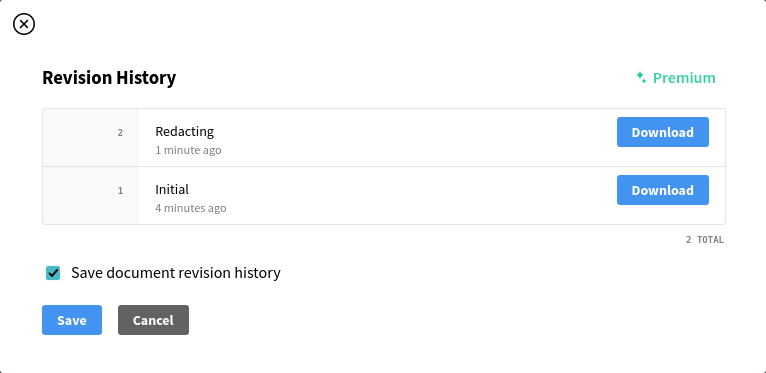
Release Notes: Document revision control, improved free transcription tools, and other improvements
DocumentCloud premium users can now utilize revision control to store document changes and easily retrieve previous versions. The platform’s sidebar has undergone a redesign, while additional improvements include dropdown menu support in Add-Ons and the ability to select which Whisper model you would like to use with the Transcribe Audio Add-On.