MuckRock’s tech team has been hard at work enhancing our transparency platforms, all of which are open source. Notable updates include improved revision control, a range of new and upgraded Add-Ons and some experiments with an open-source, self-hosted map stack.
DocumentCloud updates
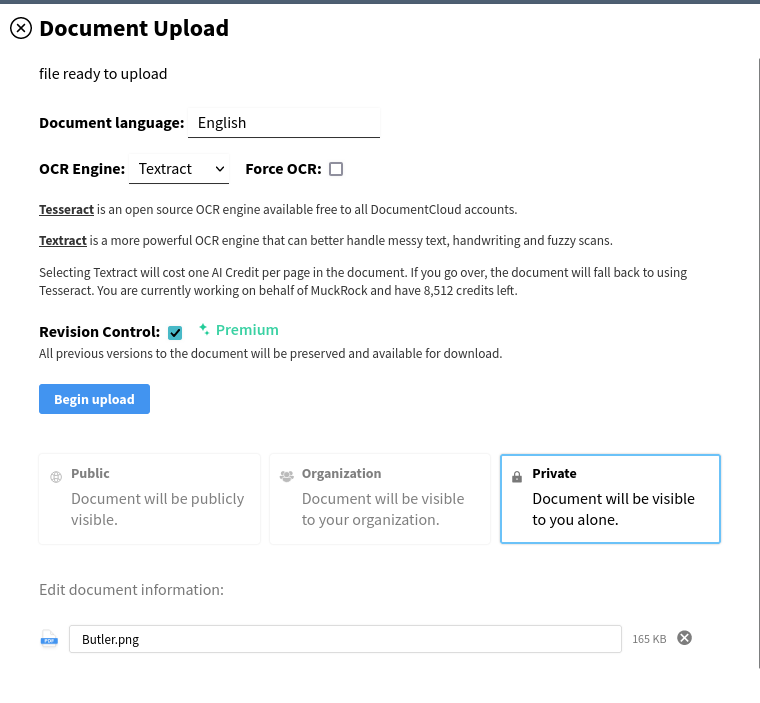
We recently launched revision control in DocumentCloud for all paid accounts. When enabled, revision control captures every update to a document and allows you to download previous versions of a document. We made some adjustments so that if you upload a non-PDF, revision control now also preserves that original file (including its metadata).
Only the uploader and those with edit access to a document have access to revision control-captured files.
DocumentCloud Add-Ons
In addition to DocumentCloud’s built-in functionality, it’s easy to extend the platform in a range of exciting directions using DocumentCloud Add-Ons. Users can browse over 50 Add-Ons from MuckRock staff as well as contributors, most of which offer additional free functionality. If you’re interested in helping push DocumentCloud’s boundaries, you can read about developing an Add-On yourself.
Klaxon
A bug report was filed to the team about receiving Klaxon alerts for superficial changes on a page. The cause of the issue was found to be content delivery networks would give certain assets on a site unique values each time that the page was refreshed, which Klaxon would detect as a change. One way to mitigate this is to pick a more specific selector for the page. We have also implemented a new field in Klaxon- a filter that now allows you to specify elements you would like to ignore to silence extraneous alerts. For example, if links on the page are superficially changing every time, you can choose to exclude <a> tags from comparison every time, while changes on the rest of the elements will still give you an alert.
Premium Add-Ons
Premium Add-Ons now have better error handling if a user has insufficient credits to run the Add-On on the specified document set.
The Azure Document Intelligence and Google Cloud Vision OCR Add-Ons additionally now better handle performing OCR on really large documents (>1000 pages) by batching the page text updates to prevent errors.
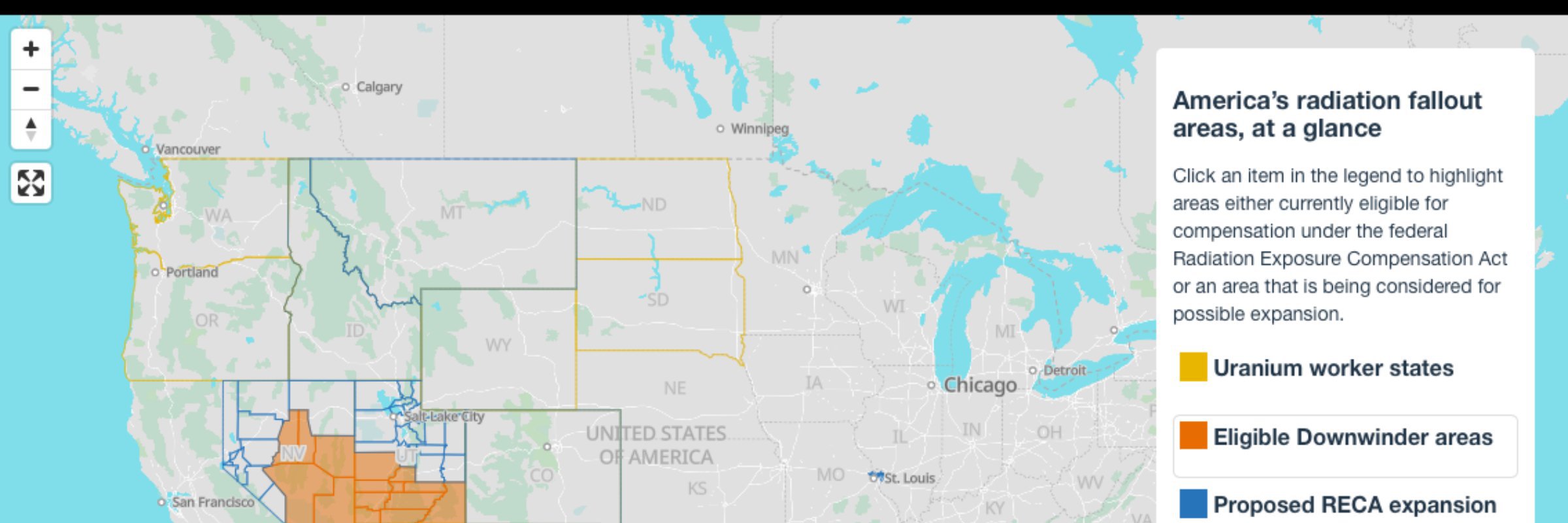
MuckRock Mapping
Our Atomic Radius project uses Protomaps, a framework that lets us self-host the underlying mapping data on our own infrastructure, and MapLibre, an open-source rendering engine. The code behind that map is available on Github.
We’re in the early days of this experiment, but we’re excited about the possibilities that come with building a self-hosted map stack. As we build new maps, we plan on documenting our process so other newsrooms can replicate what we’re doing.