In the last two weeks, MuckRock’s tech team has been hard at work enhancing the DocumentCloud platform. Notable updates include an improved method for changing the access level of documents in DocumentCloud, a range of new and upgraded Add-Ons and revamped functional tests for DocumentCloud’s frontend.
You can read previous Release Notes here.
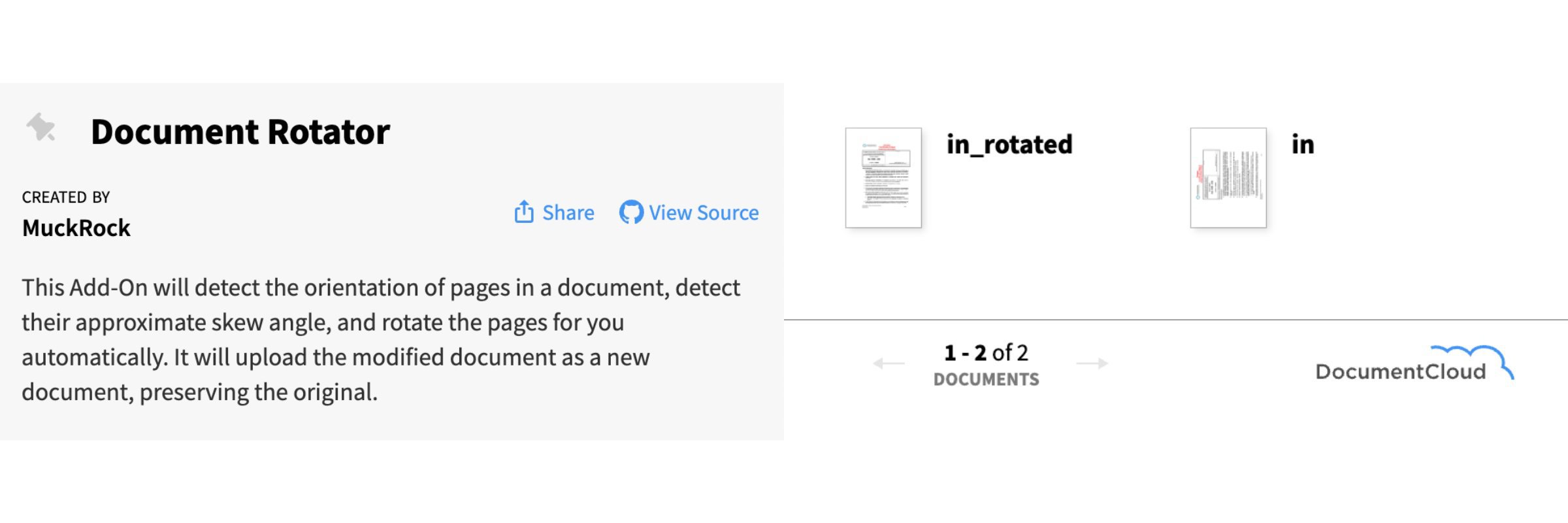
Have documents that were scanned in in every direction? Document Rotator is here to help.
Need something permanently available? The Push to IPFS/Filecoin Add-On now uses web3.storage.
We’ve also got other improvements: The Transcribe Audio Add-On now supports transcribing Facebook videos; the Azure Document Intelligence OCR Add-On now supports processing private documents and the Scraper Add-On handles Google Drive links. Finally, a fix has been pushed to our account management tool to address an issue where emails misquoted the number of AI credits and requests allocated for professional users upon subscribing.
DocumentCloud
One of our Gateway Grantees, Aos Fatos, was trying to make their collection of over 2,000 multi-thousand page documents public for the first time, and the tech team discovered some stalling issues when trying to update the visibility of documents for large document sets. The method for updating access level for documents on DocumentCloud got a re-write, making it more scalable for large quantities of big documents.
In a more behind-the-scenes update, the DocumentCloud frontend now features a revamped functional test suite that runs with each modification, reducing the likelihood of shipping bugs to production. Improving the way we test changes to DocumentCloud provides a smoother experience for our users and easier on-boarding for open source contributions to the platform.
Add-Ons
Add-Ons are extensions to DocumentCloud that give our document hosting and analysis platform new capabilities — everything from removing bad redactions to extracting data from PDFs. Most are free to use, and any DocumentCloud user can write their own and share them with others. Learn more here.
Some updates from the past few weeks:
Document Rotator
Document Rotator is a new Add-On that allows you to detect the orientation of pages in a document and auto-rotate the pages. It uploads a new version of the document in a project of your choice with the correctly oriented pages and preserves the original document. The Add-On uses OpenCV and probabilistic Hough line transforms to detect the skew angle of the page and apply the correct tilt to the document to align the pages. OCR engines perform better at correctly detecting and extracting text on documents with correctly oriented pages.
You can see the results of the rotator on a sample document in the project below:
Push to IPFS/Filecoin Add-On
The Push to IPFS Add-On retired the use of estuary as its means of uploading documents to the IPFS and filecoin networks and now uses web3.storage as a more reliable means of pushing selected documents to the InterPlanetary File System(IPFS) and the Filecoin networks for distributed, long-term storage.
Transcribe Audio
The Transcribe Audio Add-On now supports the transcription of Facebook videos.
Scraper
The Scraper Add-On now supports scraping up to 30 Google Drive documents per run, so if government agencies are posting these kinds of links, you’ll have a copy. Users can still scrape up to 100 regular documents per run.
Azure Document Intelligence OCR
The Azure Document Intelligence OCR Add-On now supports private documents. You may now run this premium OCR engine on both public and private documents with DocumentCloud Premium.
MuckRock Accounts
When signing up for a professional account, the email you receive misquotes the number of AI credits and requests. This has been fixed to reflect the correct figures.