We’ve launched several improvements over the last two weeks, including a few new DocumentCloud Add-Ons to help you extract tables from your documents and boosted DocumentCloud search stability. MuckRock’s FOIA Log Explorer now has agency cards, which provide you with more detail about each agency’s logs.
MuckRock
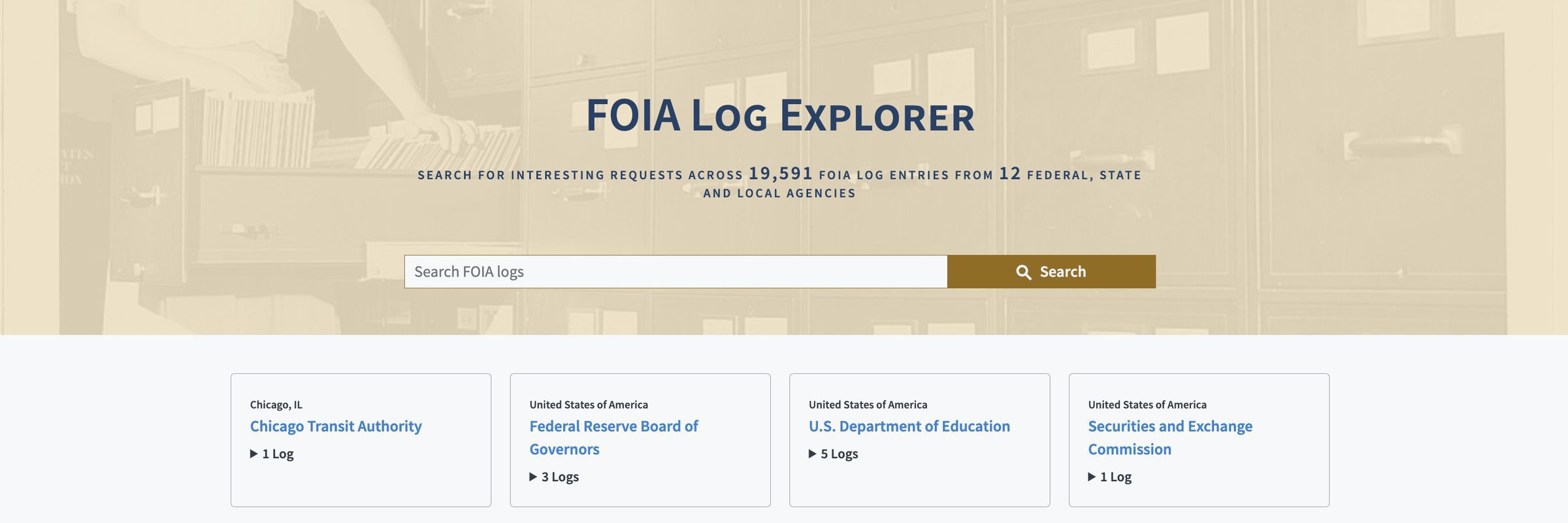
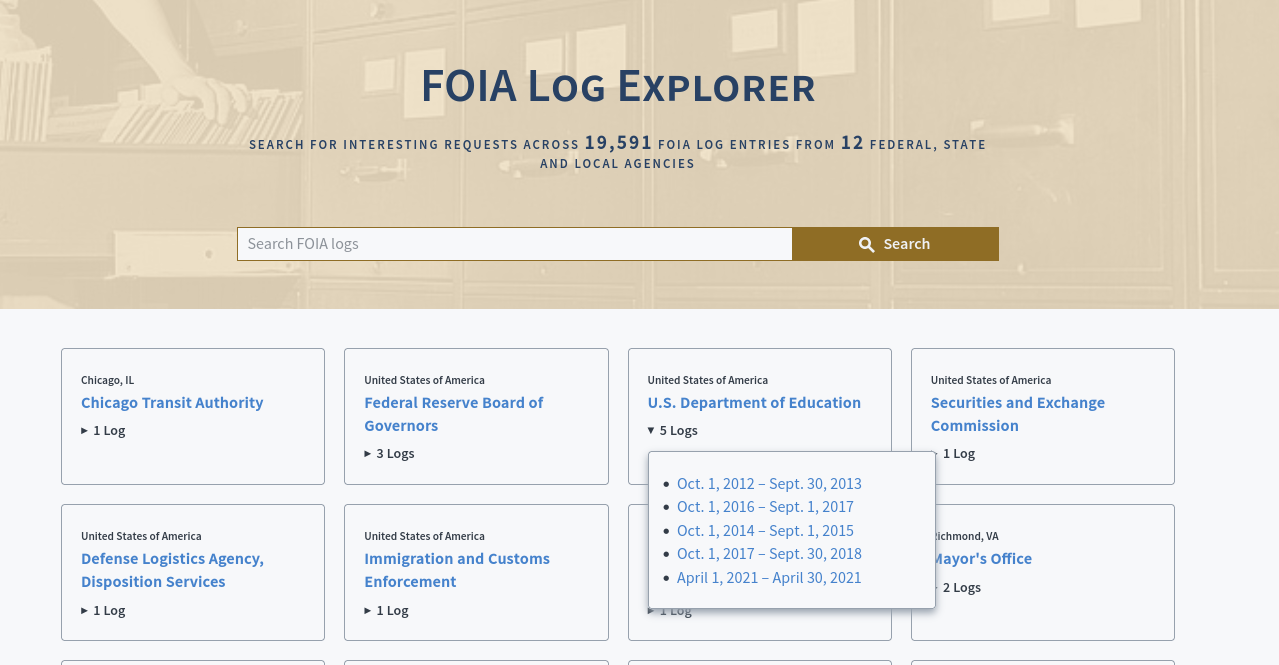
FOIA Log Explorer now includes agency cards, a dropdown view of how many logs are present for each agency with a link to each log, making it easy to see which agencies are and aren’t represented. They also let you hone in on different periods (usually a fiscal year) for a given FOIA log.
We’re always looking to add additional FOIA logs to the repository, so please share any logs you’ve dug up!
DocumentCloud
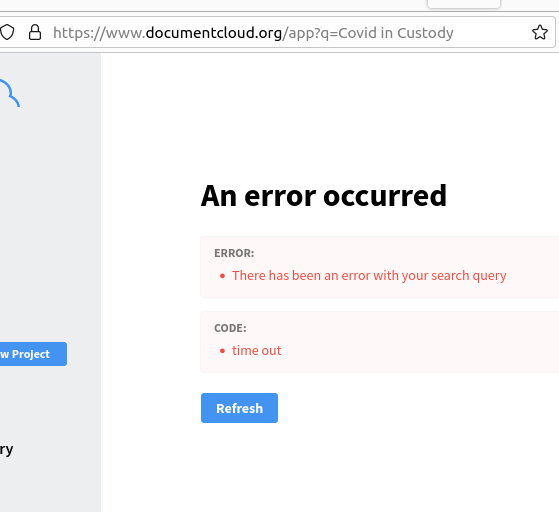
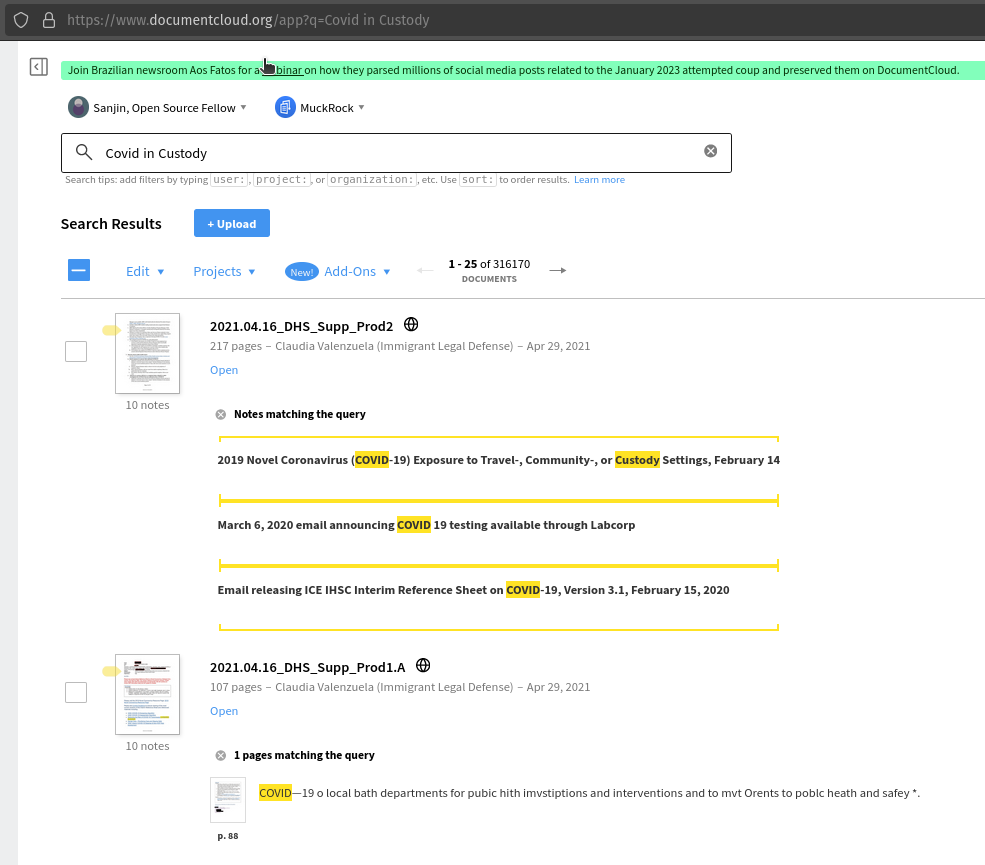
DocumentCloud search now uses stop words to deprioritize filler words like “the”, “is” and “are”. These words appear in large quantities across large document sets and slow down search results. The inclusion of filtering for stop words makes DocumentCloud more reliable and makes it so that queries fail less often. Previously, queries which included stop words would often result in a failure. With the stop words filtering this is much less common.
Before:
After:
DocumentCloud Add-Ons
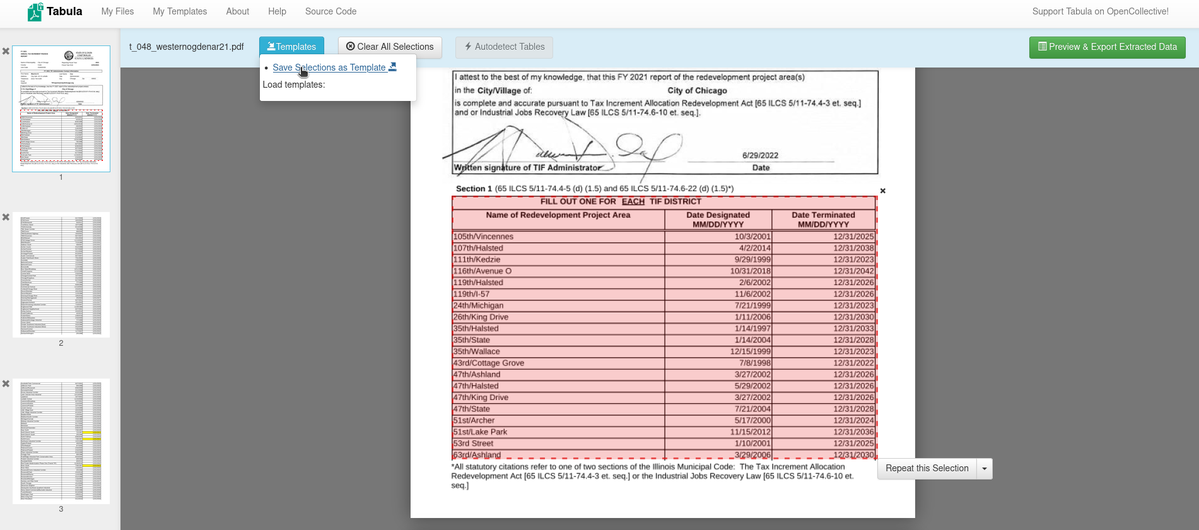
We have released four new premium Add-Ons to assist you in bulk analyzing your document sets or to extract tabular data from your document sets directly within DocumentCloud. Upgrade today to use DocumentCloud premium Add-Ons.
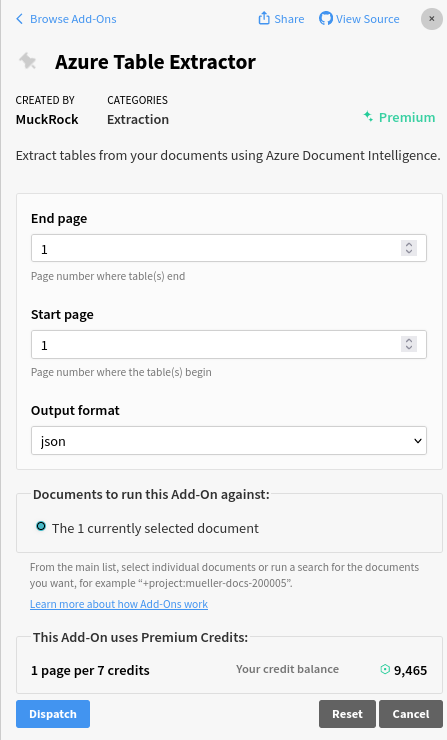
Azure Table Extractor
Azure Table Extractor allows you to extract tables from a set of pages in your document using Azure Document Intelligence’s Form Analyzer. No custom layout needs to be provided. Azure will auto-detect the boundaries of tables in your document and return you the results. Select a start and end page to extract the tables between those pages and select between a JSON or CSV output format for the tables.
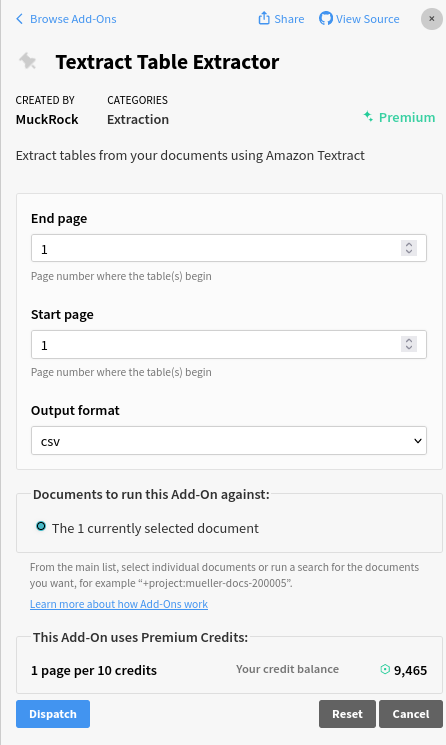
Textract Table Extractor
The Textract Table Extractor Add-On uses Amazon’s Textract service to extract tables from documents starting from a start page to an end page. Similar to Azure, no model is provided, it detects the tables automatically for you. You may choose between a CSV or an Excel file as output.
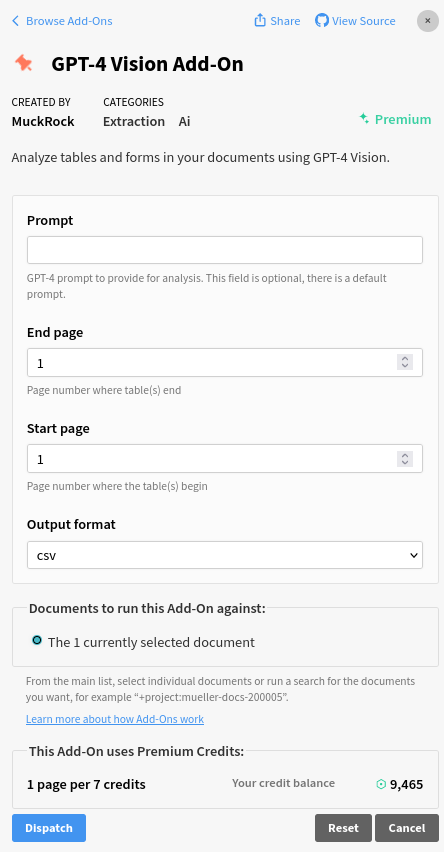
GPT-4 Vision Add-On
The GPT-4 Vision Add-On also allows you to detect and extract tabular data from your documents using GPT-4’s Vision service. You may provide a prompt to hone in on the information you want GPT-4 Vision to return in order to change how the output looks. Select a start and end page to extract the tables between those pages and select between a JSON or CSV output format for the tables.
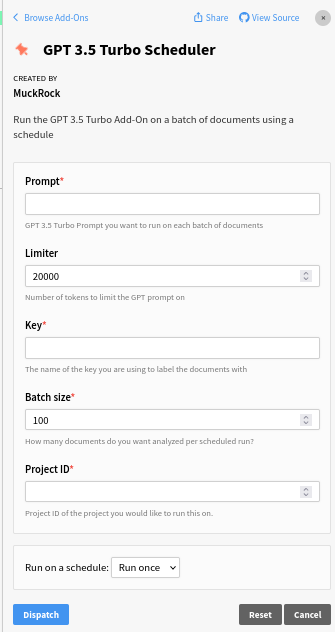
GPT 3.5 Turbo Scheduler
Add-Ons have a time limit dependent on the maximum time limit of a GitHub Actions run, which is at maximum six hours.
For users with really large document sets that they would like to analyze, our new GPT 3.5 Turbo Scheduler Add-On allows you to run our GPT 3.5 Turbo Add-On on your document set incrementally in an hourly, daily or weekly fashion. This allows you to break up your large document set into smaller subsets for analysis over time instead of trying to analyze all of the documents in the six-hour timeframe. You can select the batch size you’d like to run during each run, what prompt you would like to use, an optional limiter and a key you’d like to use to tag the completed documents.