
Teams of scholars at the Massachusetts Institute of Technology tackling bias in facial recognition technology have two recommendations for its developers: more external oversight and more representative training data.
The recommendations, presented at a recent conference on Artificial Intelligence, Ethics, and Society, come with increasing scrutiny of the use of machine learning for facial recognition, particularly by law enforcement. In letters sent last month, the ACLU and dozens of other social rights groups asked companies to cease sales of facial recognition technology to the government, citing privacy and First Amendment concerns.
The papers highlight the complexity of a problem that has also caused senators, Amazon shareholders, and algorithm developers to all call for greater scrutiny and regulation of the technology’s uses. While addressing inequalities in training data would not eliminate all of the technology’s problems, it would help solve some of its shortcomings, which in the real world can translate into discriminatory surveillance and use. Improving these systems would help mitigate some of the challenges cities and states already face in developing policies to avoid discriminatory surveillance.
Better training data, better algorithms
Analyzing the data fed to facial recognition programs could help limit, from the beginning of the process, imbalances in the technology’s results, said Alexander Amini, the co-author of “Uncovering and Mitigating Algorithmic Bias through Learned Latent Structure.” The paper introduces an algorithm to identify and mitigate overrepresentation of certain traits in computer vision and other training datasets. All machine vision algorithms built on deep learning convolutional neural networks, like the ones used for facial recognition, can suffer performance flaws when trained on photos or data that severely favors images or features representing only some of the traits it will be expected to identify.
“We tried to have our algorithm learn these underlying features of the dataset, without labels - so it’s an unsupervised learning problem - and once we understand the underlying feature of the dataset, we then try to resample it and create a new dataset which is fair in respect to these underlying features,” Amini explained. “If our algorithm contains a lot of male faces and not a lot of female faces, when we actually train our supervised algorithm - the one that actually detects faces from a not-face - we make sure that it has a fair or equal number of male faces and female faces. And you can extend this idea to other things as well, like gender to race, skin color, or even things like hair color or even if the person is wearing glasses or no glasses.”
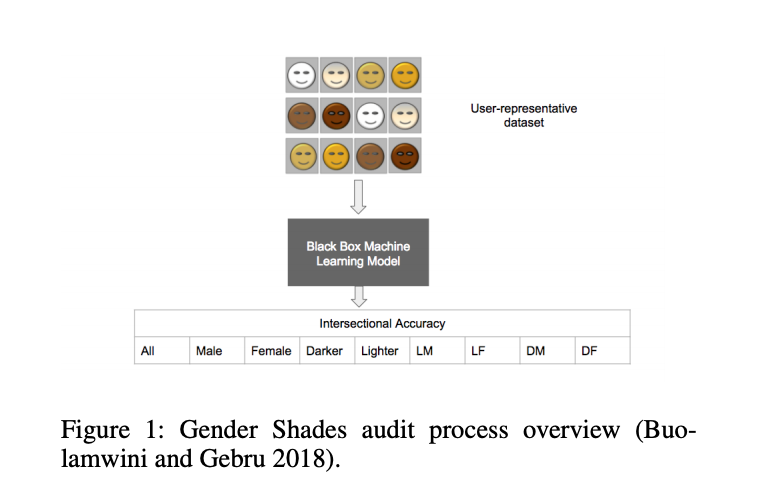
Studies have shown that some facial recognition technology is significantly more accurate when identifying light-skinned individuals. These have contributed to concerns that, when used by law enforcement and government agencies, inaccuracies will perpetuate racial biases already present in those systems. Gender Shades, a study co-authored last year by Joy Buolamwini, a researcher at MIT’s Media Lab, highlighted inaccuracies in software from Microsoft, IBM, and Face++, using a controlled database of representative faces called the Pilot Parliaments Benchmark. A collection 1,270 frontward-facing photos of international legislators from three African and three European countries, the PPB was selected as a representative array of gender and skin types and used as a control training group. In “Uncovering and Mitigating Algorithmic Bias through Learned Latent Structure,” Amini and his co-author Ava Soleimany used the PPB to test the usefulness of the “de-biasing” algorithm.

“According to the data that we give them, they’re learning all of the biases that we give them. So to call these algorithms biased, in some sense, is almost not fair. It’s our fault for giving them improperly-vetted datasets. And that’s one of the things that we tried to tackle in this project,” said Amini. And one of the things we wanted to do was to see if we could have our algorithm understand and learn from the potential biases that exist in the dataset so it could use those to learn to correct itself during training, so that it could improve its own self during training and learn to not be biased with respect to those certain categories.”
By using the algorithm to adjust the representation of certain features of the dataset, the researchers were able to create a more equitable assortment of training faces. Though these adjustments help, they won’t solve the bias problem. The sort of mechanisms being used in facial recognition algorithms perform better when trained with massive data sets. Running the algorithm on existing datasets ultimately results in more representative but smaller sets of data, highlighting the limitations of simply adding more photos to training data.
For example, Amazon has claimed that its technology is trained using over a million photos. Given the complexity of identifying faces in different contexts, lighting, and with different accessories, it’s easy for “pockets” of bias to develop within a given model, and a million photos of, for example, white males won’t be as useful to training algorithms as a smaller assortment containing photos representing a variety of skin tones and genders.
Sunlight is the best disinfectant
Buolamwini published a follow up to the Gender Shades study, Actionable Auditing: Investigating the Impact of Publicly Naming Biased Performance Results of Commercial AI Products, also released last month. It found that subjecting an agency or company to an external audit has had a measurable effect on its efforts to improve the technology’s accuracy
Three companies highlighted in Gender Shades — Microsoft, IBM, and Face++ — released major improvements regarding reducing bias in their algorithms following the paper, explicitly crediting the study with provoking the changes. Two companies not included in the first audit — Kairos and Amazon — were found to have performance disparities similar to what the other companies had before they released improvements.
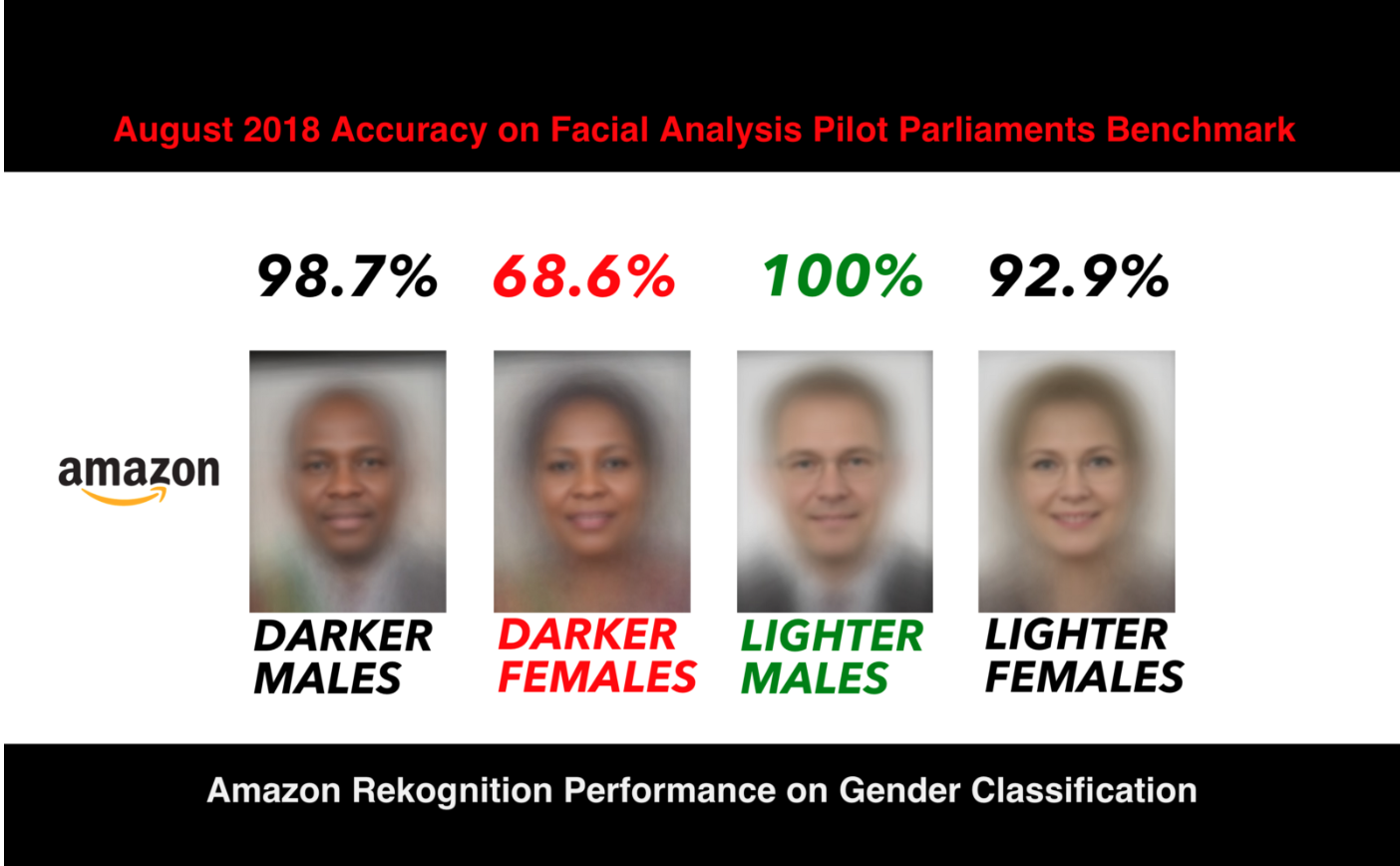
Amazon, whose Rekognition software was not part of this study, has been criticized for continued facial recognition problems. Though Rekognition is better-performing that competitors in certain categories - correctly identifying 100 percent of white male faces in the “Actionable Auditing” study - it remains inscrutable by third-party researchers even as the company actively markets its use to police departments and federal agencies. The study also found that Rekognition error rates were as high as 31.4 percent when analyzing dark-skinned female faces, for example.
Amazon has defended its relationship with government agencies and has repeatedly assured the public that the software is only recommended for use in situations where the software’s self-assessed confidence levels are at least 99 percent.
In response to Buolamwini’s most recent paper, Matt Wood, general manager of Amazon Web Services, wrote in a recent blog post that “to date (over two years after releasing the service), we have had no reported law enforcement misuses of Amazon Rekognition.”
Wood also discounted the relevance of the Amazon program used in the paper, stating that it has since been upgraded.
In a response on Medium, Buolamwini wrote, “Even when companies announce technical improvements, older versions of their AI services may still be in use. Like a car recall, the new models may have new problems and the older models persist.”
“My question to Amazon and any company that releases a new system is what is the adoption rate and how many customers are still using previous versions? For any publicly funded agencies using or thinking about using Amazon services, they need to check the different versions and demand external testing of those versions for bias.”
For Buolamwini, even resolving the accuracy issues would not be enough to protect civil liberties from the challenges presented by facial recognition.
“[W]e have to keep in mind that the AI services the company provides to law enforcement and other customers can be abused regardless of accuracy,” she wrote in support of law enforcement moratoriums on the technology. “Among the most concerning uses of facial analysis technology involve the bolstering of mass surveillance, the weaponization of AI, and harmful discrimination in law enforcement contexts. The technology needs oversight and regulation.”
Amini’s paper is embedded below.

Algorithmic Control by MuckRock Foundation is licensed under a Creative Commons Attribution 4.0 International License.
Based on a work at https://www.muckrock.com/project/algorithmic-control-automated-decisionmaking-in-americas-cities-84/.
Image by Christopher Harting via MIT News and is licensed under CC BY-NC-ND 3.0



