
Early this year, MuckRock was invited to participate in the JournalismAI Collab, working with other news organizations across the Americas to export, test, and develop new ways to apply AI and machine learning to investigative challenges. We partnered with CLIP, Ojo Público, and La Nación to get further feedback and continue developing Sidekick, and these pieces share the results of this collaboration. Read the other pieces, available in both English and Spanish, on the DockIns project page.
As journalists dealing with data and document sets, we find that the most interesting information is usually hidden in large, unstructured, and incomplete sets of documents. Especially information in public contracts: what the government is buying, how much money is being spent, and who are the suppliers.
To answer these questions, four media organizations joined forces under the JournalismAI Collab and experimented with different machine learning tools and techniques in order to build a platform that helps investigative reporters understand and process unstructured documents to get useful insights. This platform ended up being “Dockins”.
We concluded that Named Entity Recognition (NER) can be useful to easily identify the key elements in a set of documents, like names of people, places, brands, or monetary values.
That is why we tested two NER models for documents in Spanish: SpaCy and DocumentCloud (which uses Google Cloud Natural Language) on Ministry of Security procurement documents published in the Argentine official gazette.
For this benchmarking we followed these steps:
- Extracting and sampling Argentine Official Gazette documents.
- Tagging the sample’s entities manually using Amazon Sagemaker.
- Applying Named Entity Recognition on the same sample using SpaCy.
- Applying Named Entity Recognition on the same sample using Document Cloud (Google Cloud Natural Language).
- Evaluating both models’ performance.
- Analyzing errors on both models.
Extracting and sampling Argentine official gazette documents
The Boletín Oficial de la República Argentina (BORA) is the official gazette in which the Argentine government publishes its legal norms and other government acts from the legislative, executive, and judicial powers.
In this gazette, there’s a section in which almost all tenders and contracts are published in unstructured documents. We focused on these documents because there’s an official platform where contracts are published in open format but not all of them can be found.
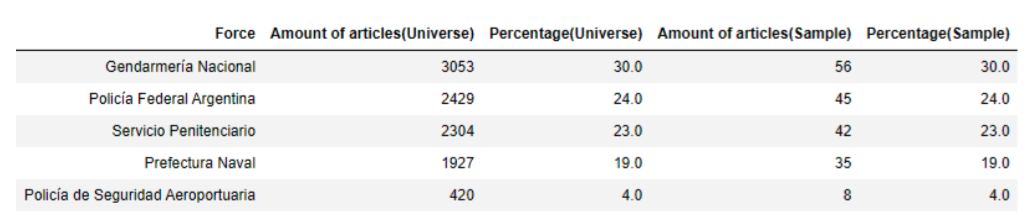
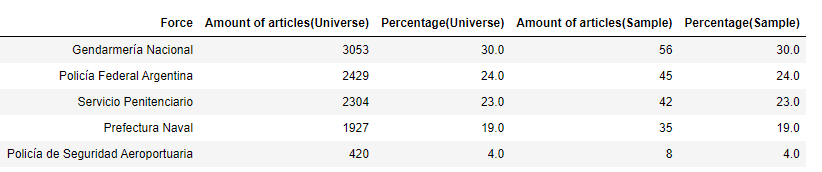
We scraped 10,133 documents from this gazette from 2014 until September 2021 that contained any information about tenders, contracts, and purchases from the Ministry of Security and its five forces (Gendarmería Nacional, Policía Federal Argentina, Servicio Penitenciario, Prefectura Naval, and Policía de Seguridad Aeroportuaria).
Then, we did a stratified sample proportional to the force category with a 90% of confidence level and a 6% margin of error.
Tagging entities of the sample manually
In order to compare the performance of the two NER models, we needed to identify in the sample which entities each document had and where they were. For this step, we did a manual tagging on the 186 documents from the sample with Amazon Sagemaker, an AWS service that allows the user to build and train machine learning models, with five labels: Place, Organization, Event, People, Other.
Once we finished, we obtained a JSON file from the tool with the document id, the entities, its labels, and positions (start and end).

Applying Named Entity Recognition on the same sample using SpaCy
After the manual tagging, we used spaCy, a free open-source library for Natural Language Processing in Python,. It has different downloadable pretrained pipelines and weights for many languages. In this case, we worked with spaCy 3.0 Spanish pipeline small to recognize entities on the same documents used for the previous step.
We also used the pandas library to read the sample csv and generate the output.
It is very easy to implement and run:
- Install spaCy’s library. Here you can find the instructions to do it.
- Choose the pipeline you want to use and download it.
- Import spaCy’s library and pandas library to your notebook:

- Read the data you want to use (using pandas):

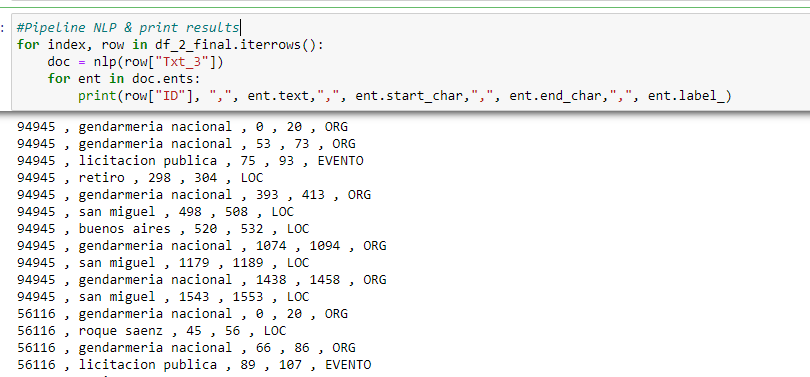
- Run NLP pipeline:
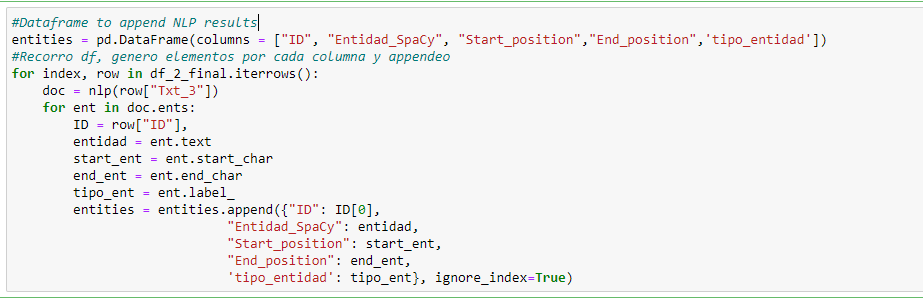
- Generate a Dataframe with the NLP results: after running the pipeline we generate a dataframe with the document id, the entities, its labels, and positions (start and end)
- Download dataframe as a CSV file:

Applying Named Entity Recognition on the same sample using DocumentCloud (Google Cloud Natural Language).
For our other test, we used the Document Cloud API to extract the entities from the BORA documents sample. Document Cloud uses Google Cloud Natural Language to recognize and extract entities from a set of documents.
To query the DocumentCloud API with Python language, first we had to install the [python-documentcloud] library. Once the access to DocumentCloud (user - password - Project ID) was configured, we went through the project documents one by one and made the request to the specific endpoint of the API that responds with the entities of each document.
We obtained a JSON file from this process with the document id, the entities, its labels, and positions (start and end).
Evaluating both models’ performance
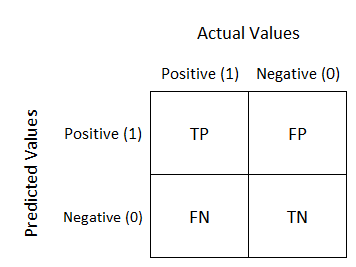
In order to evaluate the performance of the models, we compared the entities from the manual labeling with the ones from SpaCy identification, on the one side, and with the ones detected by Document Cloud, on the other side. This comparison is done in a table layout that allows visualization of the performance of an algorithm, called Confusion Matrix.
For each entity from the same document, we calculated Levenshtein distance (a number that tells you how different two strings are) between each other. For this task, we used fuzzywuzzy library.
Those entities whose Levenshtein distance was equal to or greater than 70 were considered as true positives. Entities that were found by the model and were not in the manually labeled dataset or whose Levenshtein distance was less than 70, were considered false positives. Entities not found by the model that were in the manually labeled dataset, or whose Levenshtein distance was less than 70 were considered false negatives.
Then we calculated Recall, Precision, and F1 Score, three common-used metrics to evaluate the performance of supervised models.
Precision: the ratio of correctly predicted positive observations to the total predicted positive observations. Recall: the ratio of correctly predicted positive observations to all observations in the actual class. F1 score: the weighted average of Precision and Recall. Therefore, this score takes both false positives and false negatives into account. The closer to 1, the better performs the model.
Here’s the initial results we obtained for spaCy:
Precision = 0.014 Recall = 0.095 F1score = 0.025
Here’s the initial results we obtained for DocumentCloud (Google Cloud API):
Precision = 0.044 Recall = 0.138 F1score = 0.067
Error analysis on both models
In both models we found that :
a) For some entities that humans tagged as singular ones, both NER solutions divided them into parts. For example, those documents which were from “Gendarmería Nacional - Departamento de Compras”, the model tended to recognize two entities: “Gendarmeria Nacional” from one side and “Departamento de Compras” from the other one.
b) Outputs differed in the type of entities. Eg: dates and amounts of money were recognized by Google’s entity extractor but not by SpaCy. Also, those types of entities were not considered in the manual tagging. So we didn’t take into account dates or amounts of money when comparing the two methods.
c) BORA texts’ are official communications but not press releases. So, these texts seem to be isolated sentences that were pasted in one paragraph. These type of texts are very difficult for NLP models since they don´t follow common drafting.
When using DocumentCloud’s tool, we weren’t able to customize Google’s API model in order to better recognize entities in our sample. With SpaCy, we were able to use the pipeline component called Entity ruler to help boost the model’s accuracy. For the EntityRuler, we created a dictionary of entities with their types. It contained entities such as departments and provinces of Argentina, Ministry of Security’s departments, types of auctions, among others.
After the EntityRuler implementation, we added another two changes to help the spaCy entity recognizer: lowercased the text inside the documents and removed accent marks because the model tended to recognize many capitalized words that were not entities and not all of them contained the accent mark. These three changes helped the model and we ended with a better F1 score: from the 0.025 mentioned above to 0.078.
As mentioned above, the F1 score should be closer to 1 rather than 0. The final scores are not very promising, but we are aware that the main problem remains on the entities considered by human criteria as one, but detected by the models as two different ones.
We believe that further investigation or another human tagging strategy will help us better understand SpaCy’s and DocumentCloud’s performance on these types of documents.
Nevertheless, NLP models change their performance depending on the type of texts they’re applied. That’s why we encourage the community to try them in other kinds of documents and solutions.
This project is part of the 2021 JournalismAI Collab Challenges, a global initiative that brings together media organizations to explore innovative solutions to improve journalism via the use of AI technologies.
It was developed as part of the Americas cohort of the Collab Challenges that focused on “How might we use AI technologies to innovate newsgathering and investigative reporting techniques?” with the support of the Knight Lab at Northwestern University.
JournalismAI is a project of Polis – the journalism think-tank at the London School of Economics and Political Science – and it’s sponsored by the Google News Initiative. If you want to know more about the Collab Challenges and other JournalismAI activities, sign up for the newsletter or get in touch with the team via hello@journalismai.info.
Header image via Shutterstock under commercial license.



