
Last weekend Michael and I headed to a FOIA Hackathon hosted by the BuzzFeed Open Lab, bringing MuckRock’s data — all 112GB of it — along with us. We ended the day amazed by what everyone had done with it. Lots of projects approached our agency and request data in ways that I never would have thought of or expected.
- Hannah Wallach ran “topic modeling” on the text of requests made through MuckRock. There wasn’t enough time, but she hopes to compare topics against fulfillment time, to see if some topics take longer to get documents than others.
- Rich Jones, the MuckRock user who released ODB’s FBI file, explored our data using the Caravel software, revealing patterns in agency behavior.
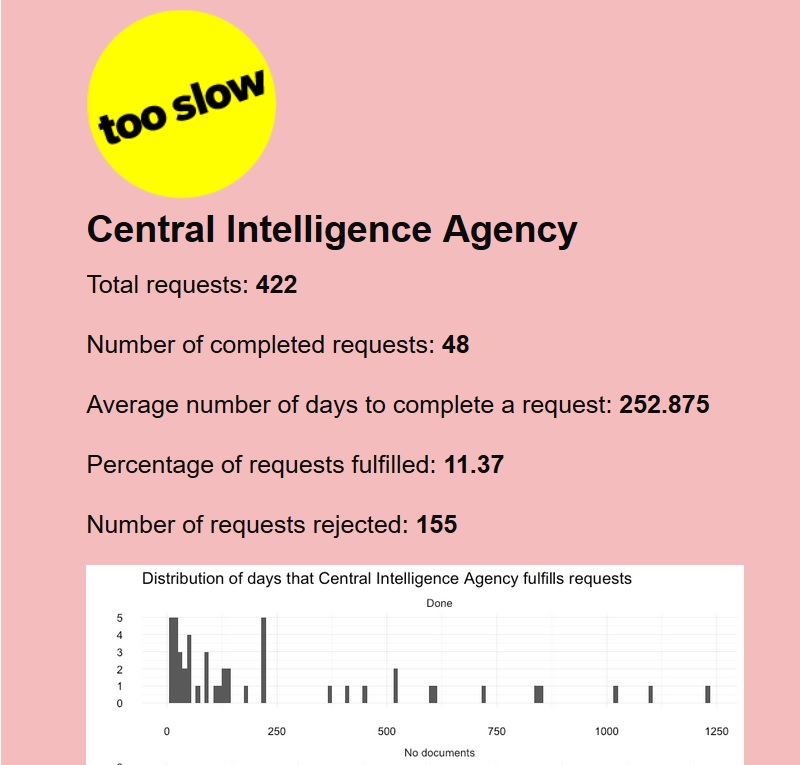
- Andrew Tran, Kai Theo, Hilary Fung, and Clint Adams analyzed all our agencies for their responsiveness and scored them, calling out agencies that are too slow to respond (cough FBI NSA CIA NYPD cough).
- Jeremy Singer-Vine analyzed the file types returned by agencies, including a fun toy to randomly grab a piece of audio returned by an agency!
- Dominic Mauro, Geoffrey Yip, and Kate Fink began to question whether states with mandatory attorney fee reimbursements had more responsive agencies.
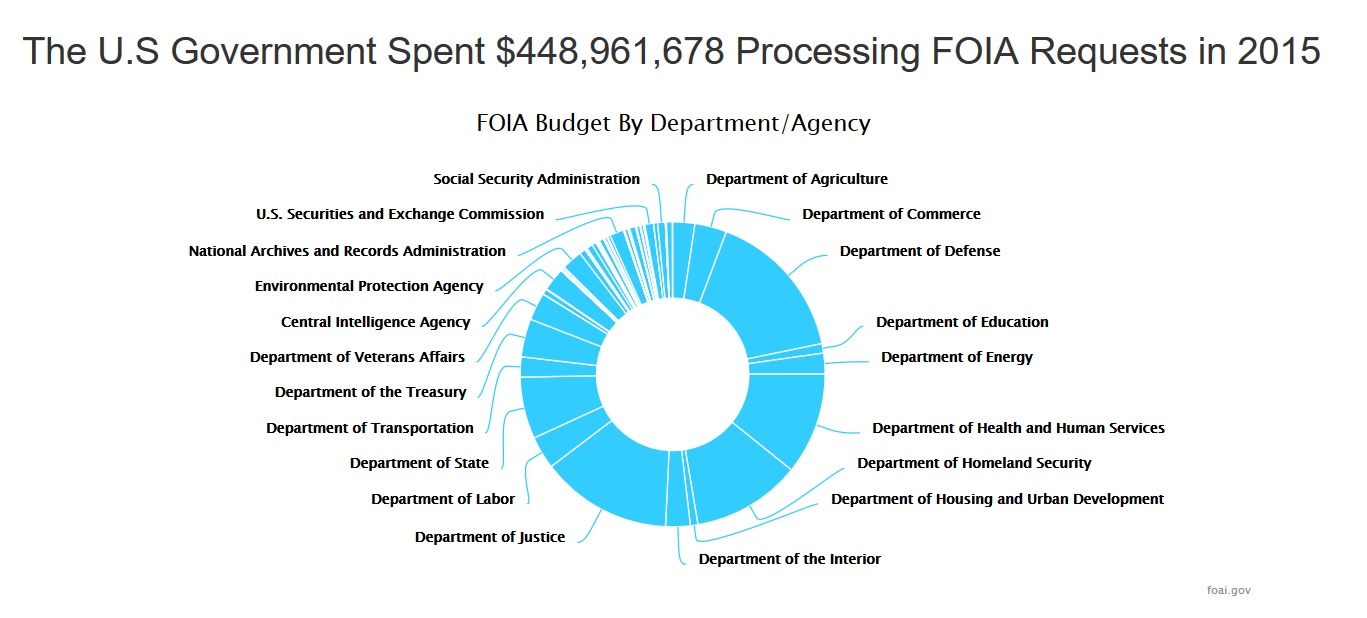
- Molly Kraus and Michael Kenney visualized data from FOIA.gov to visualize the cost and volume of Federal FOIA requests.
- Max Galka of FOIA Mapper fame examined how concentrated requests are to single requesters, finding that 38% of Federal requests are filed by the top 100 requesters.
- Kelsey Kennedy and Peter Hess questioned whether public records requests for the emails of researchers at public universities is growing.
- Ashesha Mehrotra, Poroma Pant, and Dylan Portelance began to compare and contrast FBI requests against popular topics, trying to see how the news cycle affects the content and frequency of FOIA requests.
Seeing the data from years of requests reused in new ways was a rush. It made obvious how the end of a FOIA request — whether completed with responsive documents or a straight-up rejection — is only the beginning of the story. There’s so much more to learn from the data we have on tap; it only requires a little bit of work and a lot of ingenuity.
To that end, we’re doubling down on our efforts to open-source our codebase and document our API (did you know we have an API? We totally do! Check it out!).
If you wanna start hacking on our data, check out our API examples repository. If you have any questions, reach out to me via email or Twitter.
Thank you to Amanda Hickman, Nabiha Syed, Jeremy Singer-Vine, and BuzzFeed for hosting such a great event. We’ll see you all at the next one!
Image by Michael Morisy



